Chapter 4: Ensemble Methods - The Power of Many
Ensemble Methods - The Power of Many in Understanding ML Model Relationships: From Basic Models to Ensemble Methods.
Learning Objectives
By the end of this chapter, you will be able to:
- Place Ensemble Methods - The Power of Many within the broader machine-learning model map.
- Explain how related model families solve different failure modes.
- Choose model strategies based on data shape, constraints, and goals.
Chapter 4: Ensemble Methods - The Power of Many
Discover how combining multiple models creates superior performance through bagging and boosting
Why Single Models Aren't Enough
Even with regularization, single models have inherent limitations. Each model represents one perspective on the data. What if we could combine multiple perspectives?
The Ensemble Solution
Ensemble methods combine predictions from multiple models to create a stronger predictor:
Key Insight: Individual models make different types of errors. When combined intelligently, these errors can cancel out!
Ensemble Voting Illustration
Visualization planned: multiple base models contributing votes or weighted predictions to a final ensemble decision.
Interactive Ensemble Voting Demo
Click on models to see how ensemble voting works:
Two Main Approaches
There are two fundamental ways to create ensemble models:
Bagging (Bootstrap Aggregating)
Strategy: Train models independently on different data samples
- Models trained in parallel
- Each model sees different data subset
- Final prediction: average/vote
- Reduces variance
Example: Random Forest
Boosting
Strategy: Train models sequentially, each fixing previous errors
- Models trained sequentially
- Each model focuses on previous mistakes
- Final prediction: weighted combination
- Reduces bias
Example: XGBoost
The Wisdom of Crowds Principle
Ensemble methods work because of a fundamental principle: diverse, independent predictions are often more accurate than any single prediction.
The Classic Example: Guessing the Weight of a Bull
In 1906, Francis Galton observed 787 people guessing the weight of a bull at a fair:
- Individual guesses: Widely varying, many quite wrong
- Average of all guesses: Within 1% of the actual weight!
- Key insight: Errors in different directions canceled out
Interactive Wisdom of Crowds Demo
Select different types of models to see how diversity affects ensemble performance:
High Model Diversity
Your selected models make different types of errors, leading to strong ensemble performance!
Requirements for Ensemble Success
For ensembles to work effectively, you need:
Diversity
Models should make different types of mistakes
How: Different algorithms, features, or training data
Individual Competence
Each model should be better than random
How: Proper training and validation
Independence
Models shouldn't all fail the same way
How: Different data samples or approaches
Bagging: Independent Parallel Models
Bootstrap Aggregating (Bagging) creates diverse models by training each on a different random sample of the data.
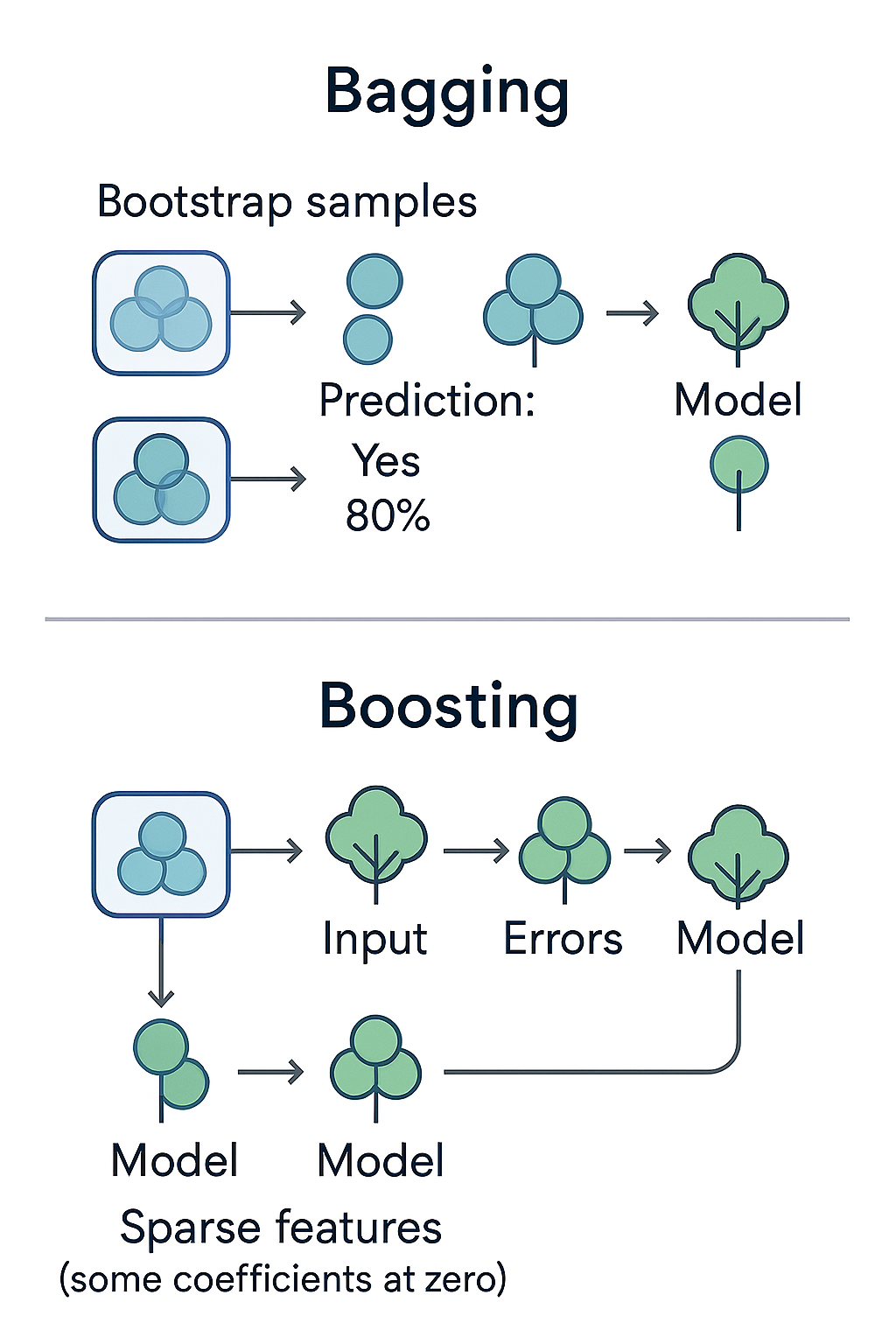
Interactive Bagging Demonstration
Watch how bagging creates diverse models from the same dataset:
1000 samples
10 × 750 samples
In Parallel
Final Result
How Bagging Works
Sample with replacement
Independent models
Average/Vote
Key Benefits:
- Variance Reduction: Averaging reduces prediction variance
- Overfitting Control: Individual overfitting gets averaged out
- Parallelizable: Models can be trained simultaneously
- Robustness: Less sensitive to outliers
When Bagging Works Best:
- Base models have high variance (like deep decision trees)
- You have sufficient data for multiple samples
- Models can be trained independently
- You want to reduce overfitting
Boosting: Sequential Error Correction
Boosting takes a different approach: train models sequentially, with each new model focusing on the errors made by previous models.
Interactive Boosting Demonstration
Watch how boosting iteratively improves predictions:
Bagging vs Boosting: The Key Differences
Bagging Characteristics
- Training: Parallel/Independent
- Focus: Reduce variance
- Base Models: Often complex (high variance)
- Combination: Simple average/majority vote
- Overfitting Risk: Lower
- Speed: Can parallelize
Boosting Characteristics
- Training: Sequential/Adaptive
- Focus: Reduce bias
- Base Models: Often simple (high bias)
- Combination: Weighted combination
- Overfitting Risk: Higher (but powerful)
- Speed: Sequential (slower)
Which Should You Choose?
- Choose Bagging when: Base models overfit, you want stability, you can parallelize
- Choose Boosting when: Base models underfit, you want maximum accuracy, you're willing to tune carefully
- In practice: Random Forest (bagging) for quick, robust results; XGBoost (boosting) for competitions and maximum performance
Chapter 4 Quiz
Test your understanding of ensemble methods: