Chapter 5: Random Forest Deep Dive
Random Forest Deep Dive in Understanding ML Model Relationships: From Basic Models to Ensemble Methods.
Learning Objectives
By the end of this chapter, you will be able to:
- Place Random Forest Deep Dive within the broader machine-learning model map.
- Explain how related model families solve different failure modes.
- Choose model strategies based on data shape, constraints, and goals.
Chapter 5: Random Forest Deep Dive
Build and understand Random Forest through interactive forest construction and feature analysis
Random Forest = Bagging + Decision Trees + Feature Randomness
Random Forest combines three powerful concepts to create one of the most robust and widely-used machine learning algorithms.
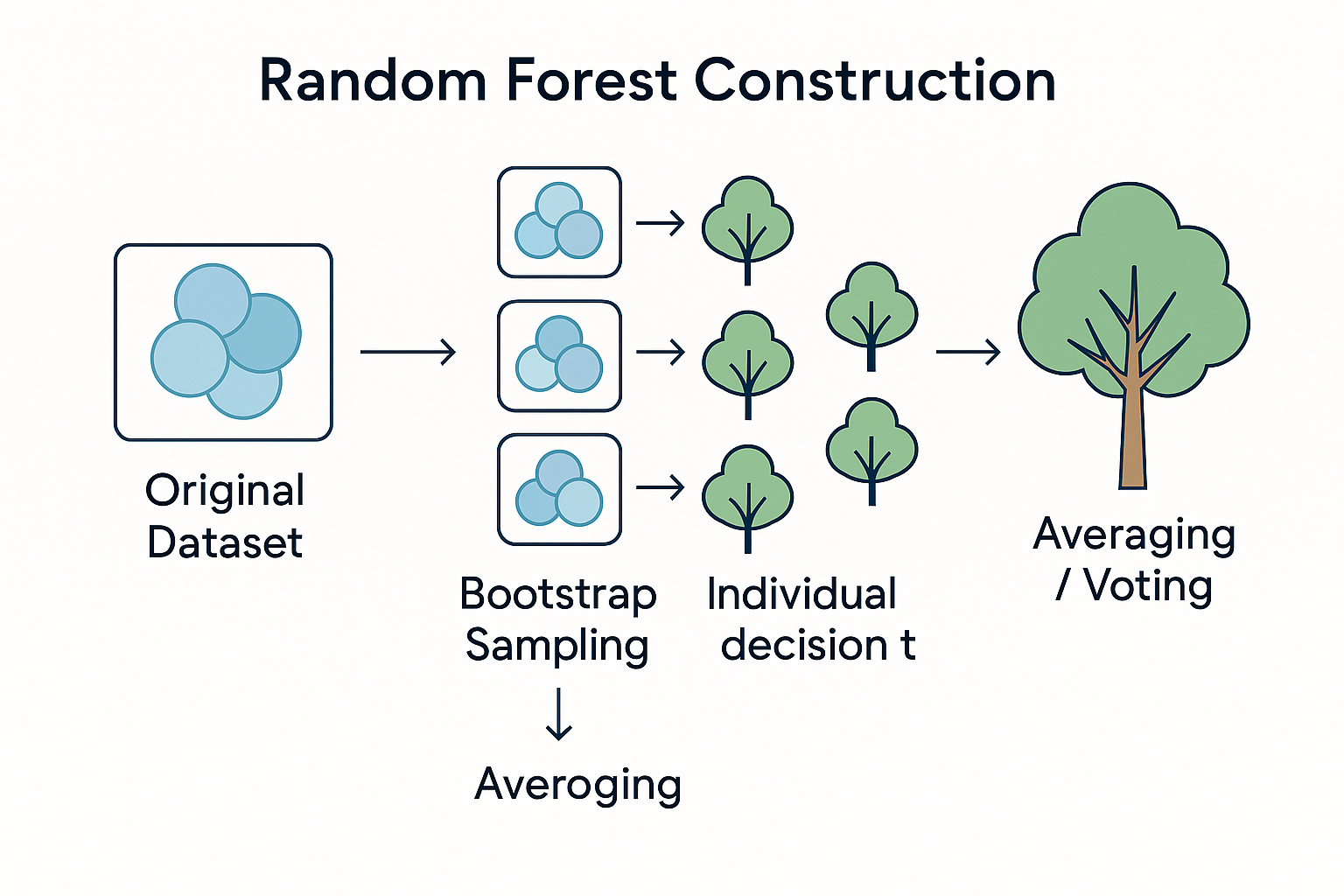
The Three Ingredients
1. Bagging
Train multiple trees on different bootstrap samples of the data
Benefit: Reduces overfitting through averaging
2. Decision Trees
Use decision trees as the base learners (usually deep trees)
Benefit: Captures complex non-linear patterns
3. Feature Randomness
Each split considers only a random subset of features
Benefit: Reduces correlation between trees
Quick Random Forest Demo
See how Random Forest makes predictions by combining tree votes:
Forest Prediction
Interactive Forest Construction
Build your own Random Forest step by step and see how different parameters affect performance.
Forest Builder
Adjust the parameters to build your custom Random Forest:
Current Configuration Analysis
Balanced configuration with good performance and moderate training time.
Key Random Forest Parameters
n_estimators (Number of Trees)
- Higher: Better performance, slower training
- Lower: Faster training, may underfit
- Typical: 100-500 trees
max_features (Feature Randomness)
- √n_features: Good default for classification
- n_features/3: Good default for regression
- Lower: More randomness, less correlation
max_depth (Tree Complexity)
- None: Trees grow until pure (default)
- Limited: Prevents individual tree overfitting
- Balance: Deep enough but not too deep
min_samples_leaf
- Higher: Smoother decision boundaries
- Lower: More detailed boundaries
- Typical: 1-10 for most problems
Bootstrap Sampling in Action
Understanding how Random Forest creates diverse training sets through bootstrap sampling is crucial to understanding why it works so well.
Bootstrap Sampling Visualization
Watch how different bootstrap samples create diverse training sets:
Sampling Statistics
Out-of-Bag (OOB) Error Estimation
A unique advantage of Random Forest: free validation without a separate test set!
How it works:
- Each bootstrap sample leaves out ~37% of data
- These "out-of-bag" samples serve as validation data
- Each tree is tested on its OOB samples
- OOB error approximates true validation error
Benefit: OOB error is very close to true validation error, giving you reliable performance estimates without setting aside validation data!
Feature Importance Analysis
Random Forest provides excellent insights into which features are most important for making predictions.
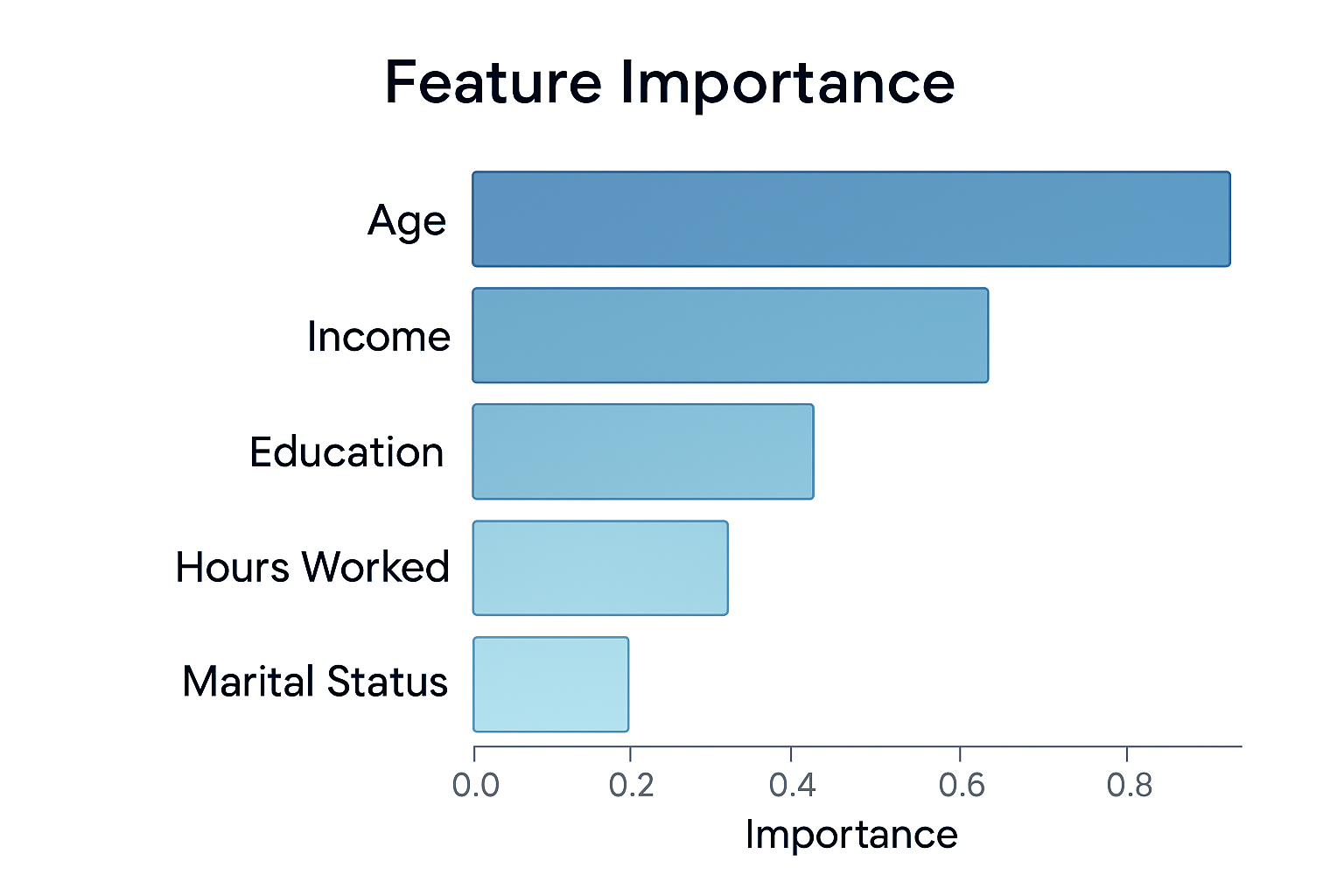
Interactive Feature Importance
Adjust model parameters to see how feature importance changes:
How Feature Importance is Calculated
- For each tree: Calculate how much each feature decreases impurity
- Weight by samples: Features used on more samples get higher scores
- Average across trees: Combine importance scores from all trees
- Normalize: Scale so all importances sum to 1.0
Hyperparameter Impact on Performance
See how different parameter combinations affect various metrics:
Random Forest Advantages & Disadvantages
Advantages
- Robust: Handles overfitting well
- No scaling needed: Works with raw features
- Mixed data types: Numerical and categorical
- Feature importance: Built-in feature ranking
- OOB estimation: Free validation
- Parallel training: Fast on multiple cores
Disadvantages
- Memory usage: Stores many trees
- Memory usage: Stores many trees
- Prediction speed: Slower than single models
- Interpretability: Hard to understand individual predictions
- Bias toward categorical features: With many categories
- Not great for linear relationships: Overkill for simple patterns
- Extrapolation: Poor performance outside training range
Disadvantages
Chapter 5 Quiz
Test your understanding of Random Forest: