Chapter 6: Gradient Boosting Mastery
Gradient Boosting Mastery in Understanding ML Model Relationships: From Basic Models to Ensemble Methods.
Learning Objectives
By the end of this chapter, you will be able to:
- Place Gradient Boosting Mastery within the broader machine-learning model map.
- Explain how related model families solve different failure modes.
- Choose model strategies based on data shape, constraints, and goals.
Chapter 6: Gradient Boosting Mastery
Master sequential learning through interactive gradient boosting demonstrations and residual analysis
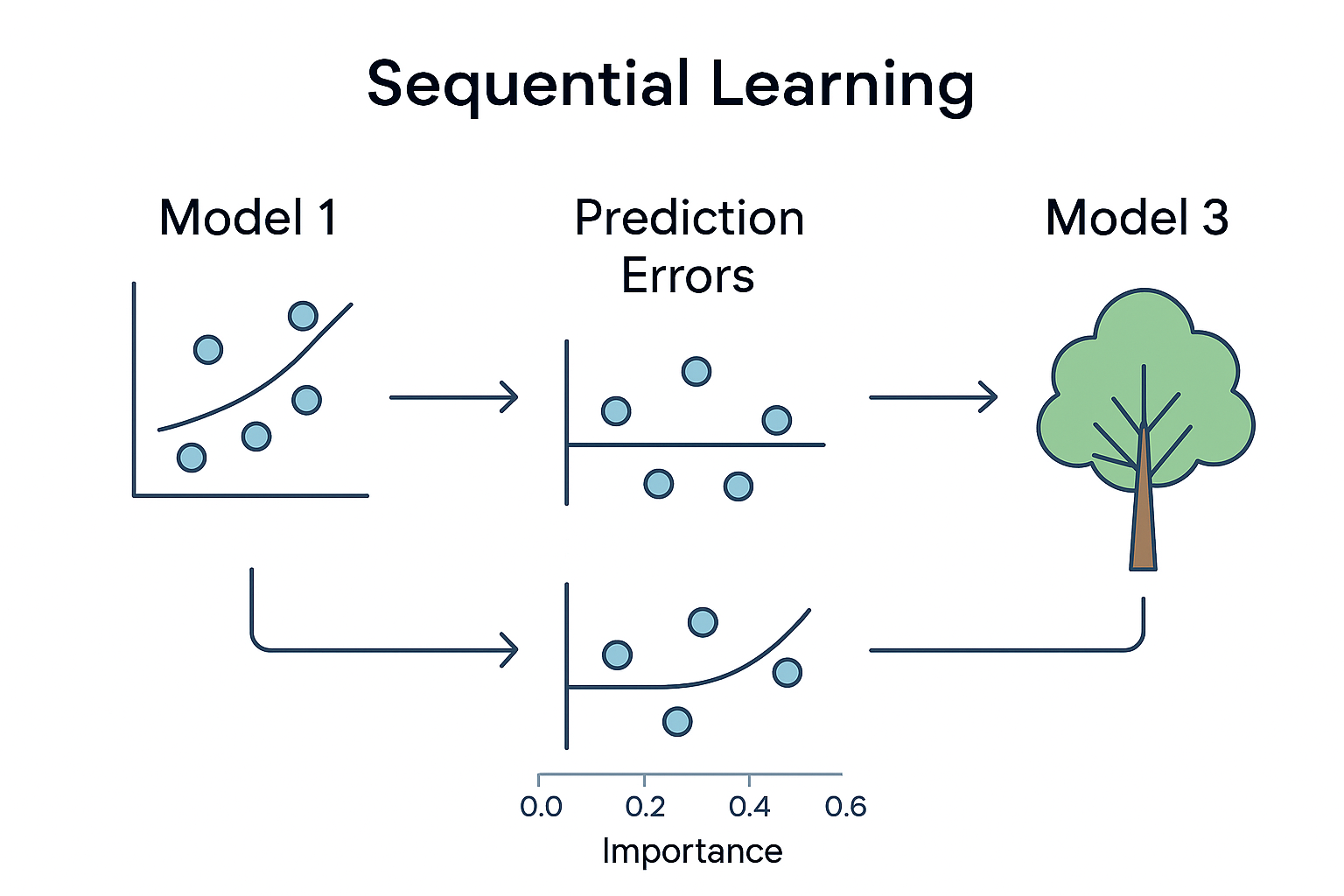
Gradient Boosting: Learning from Mistakes
Unlike Random Forest which trains trees independently, Gradient Boosting trains them sequentially, with each new tree focused on correcting the errors of previous trees.
The Core Principle
Gradient Boosting follows a simple but powerful strategy:
Where:
- Fm(x) = Current ensemble prediction
- Fm-1(x) = Previous ensemble prediction
- α = Learning rate (how much to trust the new model)
- hm(x) = New weak learner trained on residuals
Interactive Gradient Boosting Overview
Watch how prediction accuracy improves with each boosting round:
Round 1: Initial Model
First weak learner makes basic predictions. Error is high but we're just getting started!
Why "Gradient" Boosting?
The name comes from gradient descent optimization:
- Gradient: Direction of steepest increase in loss function
- Negative Gradient: Direction to minimize loss (residuals)
- Each model: Trained to predict negative gradients (residuals)
- Result: Ensemble moves in direction that minimizes loss
Sequential Learning in Action
Watch how gradient boosting builds models step-by-step, with each model learning from the mistakes of all previous models.
Step-by-Step Boosting Process
Control the learning process and see how each round improves predictions:
Weak Learners: The Building Blocks
Gradient boosting typically uses simple "weak" learners. Click to see different types:
Decision Stump
Single split tree
Most common choice
Shallow Tree
Depth 2-6 tree
Good for interactions
Linear Model
Simple linear regression
Fast and interpretable
Decision Stumps
Simple one-level decision trees that make a single split. They're weak individually but powerful when combined through boosting. Each stump slightly improves overall predictions.
Residual Analysis: Learning from Errors
The key to gradient boosting's success is its focus on residuals - the differences between actual and predicted values.
Interactive Residual Visualization
See how residuals shrink as more models are added:
Round 0: Initial Residuals
Starting with large residuals everywhere. Each subsequent model will focus on reducing these errors.
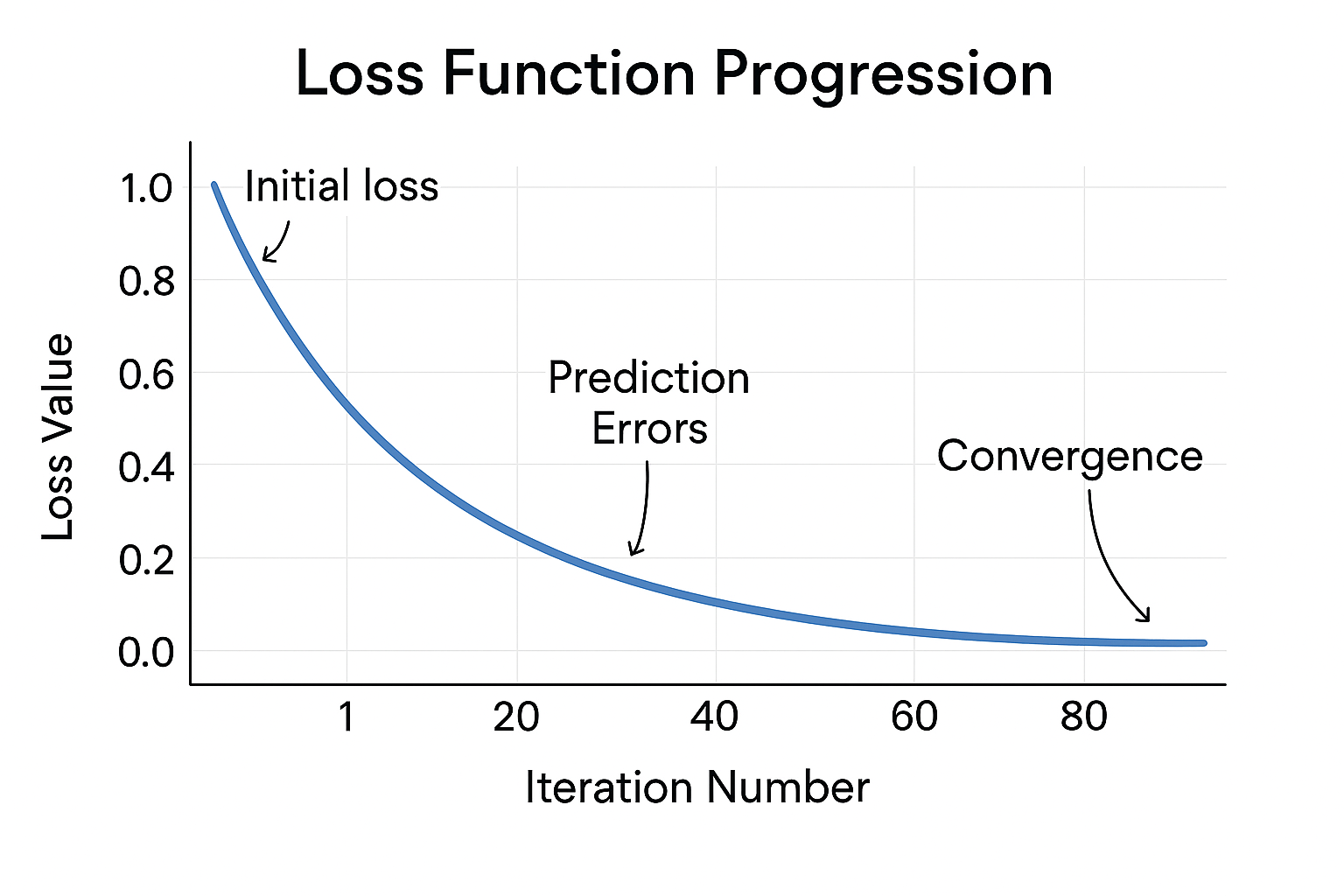
Loss Function Progression
Watch how the loss decreases with each boosting iteration:
Random Forest vs Gradient Boosting
Understanding the key differences helps you choose the right ensemble method for your specific problem.
Random Forest (Bagging)
Training Strategy
- Parallel independent training
- Bootstrap sampling
- Feature randomness
- Deep trees (high variance)
Strengths
- Less prone to overfitting
- Stable and robust
- Can be parallelized
- Good default choice
Best For
- When you want stability
- Large datasets
- Quick, robust results
- Parallel processing available
Gradient Boosting
Training Strategy
- Sequential adaptive training
- Focus on residuals
- Learning rate control
- Weak learners (low variance)
Strengths
- Often higher accuracy
- Flexible loss functions
- Handles bias well
- Feature importance
Best For
- Maximum predictive performance
- Competitions
- When you can tune carefully
- Structured/tabular data
Performance Comparison on Different Problem Types
Random Forest
Gradient Boosting
Tabular Data: Gradient Boosting typically performs better on structured data due to its sequential learning approach that can capture complex patterns.
Chapter 6 Quiz
Test your understanding of gradient boosting: