Chapter 7: XGBoost - The Champion
XGBoost - The Champion in Understanding ML Model Relationships: From Basic Models to Ensemble Methods.
Learning Objectives
By the end of this chapter, you will be able to:
- Place XGBoost - The Champion within the broader machine-learning model map.
- Explain how related model families solve different failure modes.
- Choose model strategies based on data shape, constraints, and goals.
Chapter 7: XGBoost - The Champion
Master the optimization powerhouse that dominates ML competitions and production systems
XGBoost - The Undisputed Champion
The optimization powerhouse that has won countless ML competitions
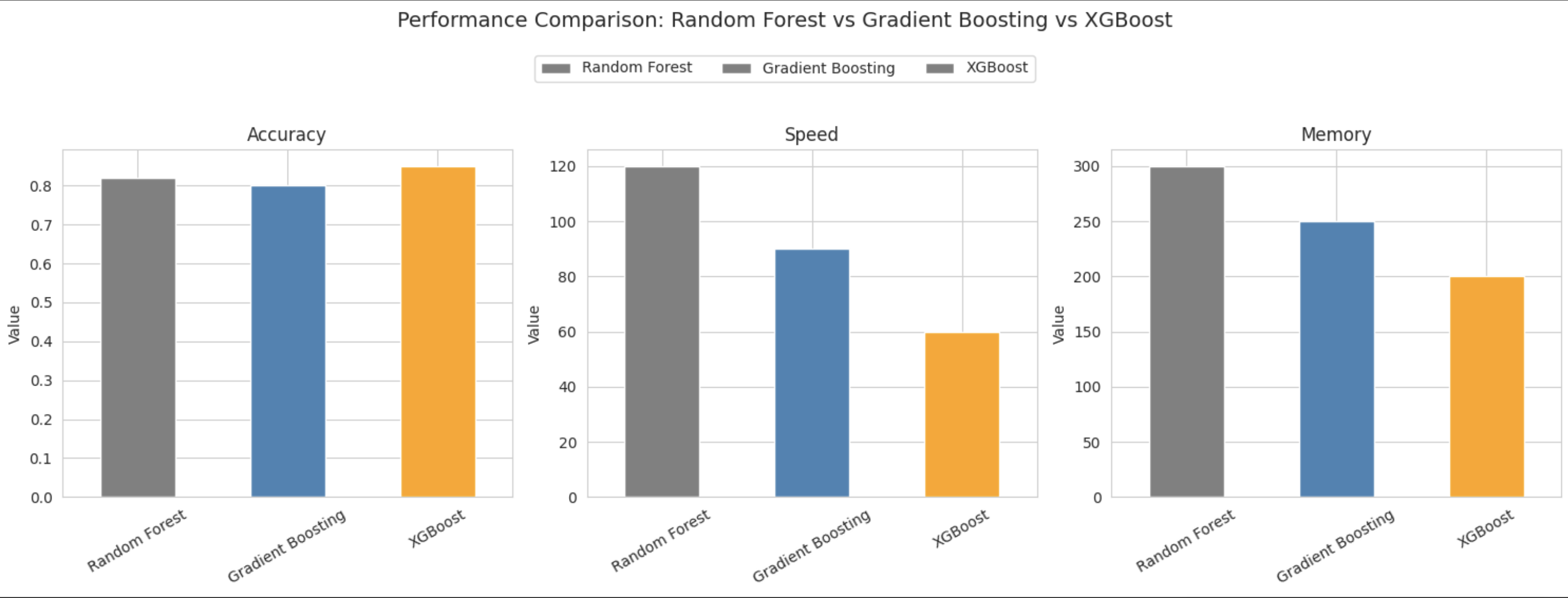
Why XGBoost Reigns Supreme
XGBoost (eXtreme Gradient Boosting) isn't just another algorithm—it's a highly optimized, scalable machine learning system that combines the best of gradient boosting with cutting-edge optimizations.
🌳 Random Forest
Solid baseline with parallel training and natural feature selection.
📈 Gradient Boosting
Sequential learning with better accuracy but slower training.
🚀 XGBoost
Best of all worlds: highest accuracy, fastest training, built-in regularization!
XGBoost Secret Weapons
🛡️ Built-in Regularization
L1 and L2 regularization prevent overfitting automatically, unlike traditional gradient boosting.
⚡ System Optimization
Parallel processing, cache optimization, and sparse matrix handling make it lightning fast.
🧠 Smart Tree Building
Level-wise tree construction and advanced pruning find the best splits efficiently.
⚖️ Missing Value Handling
Automatically learns optimal directions for missing values during training.
Hyperparameter Optimization Playground
Experience the power of XGBoost tuning through interactive parameter adjustment:
Interactive XGBoost Tuning
Adjust key hyperparameters and see real-time performance impact:
Training Progress
Performance Metrics
Feature Importance Analysis
XGBoost provides multiple ways to understand which features drive your model's predictions:
Understanding Feature Importance Types
- Gain: Average improvement in accuracy when using a feature for splits
- Split Frequency: How often each feature is used in tree splits
- Coverage: Average number of observations affected by splits on this feature
Real-World Success Stories
🏆 Kaggle Competition Dominance
XGBoost has powered victories in numerous machine learning competitions:
🏢 Production Applications
- Credit Risk Assessment: Banks use XGBoost to predict loan defaults with 94%+ accuracy
- Click-Through Prediction: Ad platforms optimize billion-dollar campaigns
- Fraud Detection: Financial institutions catch fraudulent transactions in real-time
- Customer Churn: Telecom companies predict and prevent customer attrition
- Supply Chain: E-commerce giants optimize inventory and delivery
- Healthcare: Predict patient outcomes and treatment effectiveness
✅ Perfect For XGBoost
- Tabular/structured data problems
- Medium to large datasets (1K+ samples)
- Competition or production scenarios
- When you need interpretability + performance
- Mixed data types (numerical + categorical)
- When you have time to tune hyperparameters
❌ Consider Alternatives
- Image or text data (use deep learning)
- Very small datasets (<1K samples)
- Real-time inference with strict latency
- When simplicity is more important than accuracy
- Streaming/online learning scenarios
- When interpretability is more important than performance
Chapter 7 Quiz
Test your understanding of XGBoost optimization: