Chapter 8: Putting It All Together
Putting It All Together in Understanding ML Model Relationships: From Basic Models to Ensemble Methods.
Learning Objectives
By the end of this chapter, you will be able to:
- Place Putting It All Together within the broader machine-learning model map.
- Explain how related model families solve different failure modes.
- Choose model strategies based on data shape, constraints, and goals.
Chapter 8: Putting It All Together
Master algorithm selection and integration for real-world ML success
Putting It All Together
Master algorithm selection with our interactive decision tree
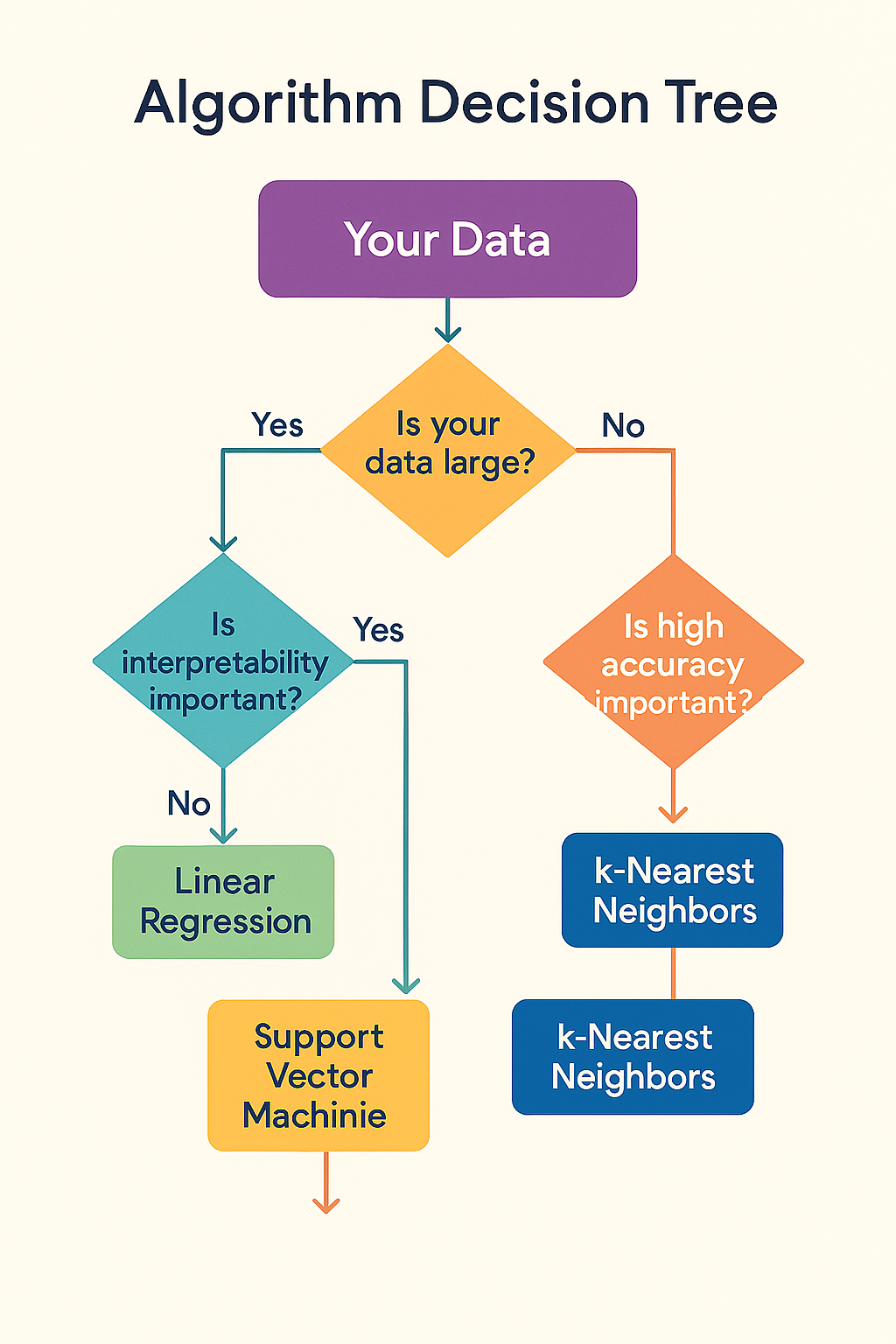
The Journey We've Taken
Throughout this tutorial, we've explored the relationships between different ML techniques. Now let's put it all together with a practical framework for choosing the right algorithm.
Interactive Algorithm Selection Tree
Answer questions about your problem to get personalized algorithm recommendations:
Key Decision Factors
📊 Data Type & Size
- Tabular data: Tree-based methods excel
- Large datasets: Consider scalability
- Small datasets: Avoid complex models
- Missing values: XGBoost handles automatically
🎯 Problem Requirements
- Accuracy priority: XGBoost or Gradient Boosting
- Interpretability: Decision Trees or Linear models
- Speed: Random Forest for balance
- Stability: Random Forest for robustness
⚡ Resource Constraints
- Limited time: Random Forest (less tuning)
- Limited compute: Linear models
- Memory constraints: Avoid deep ensembles
- Real-time inference: Consider model size
🔧 Maintenance & Deployment
- Production stability: Well-tested algorithms
- Model updates: Consider retraining cost
- Monitoring: Feature importance tracking
- Scalability: Cloud-native solutions
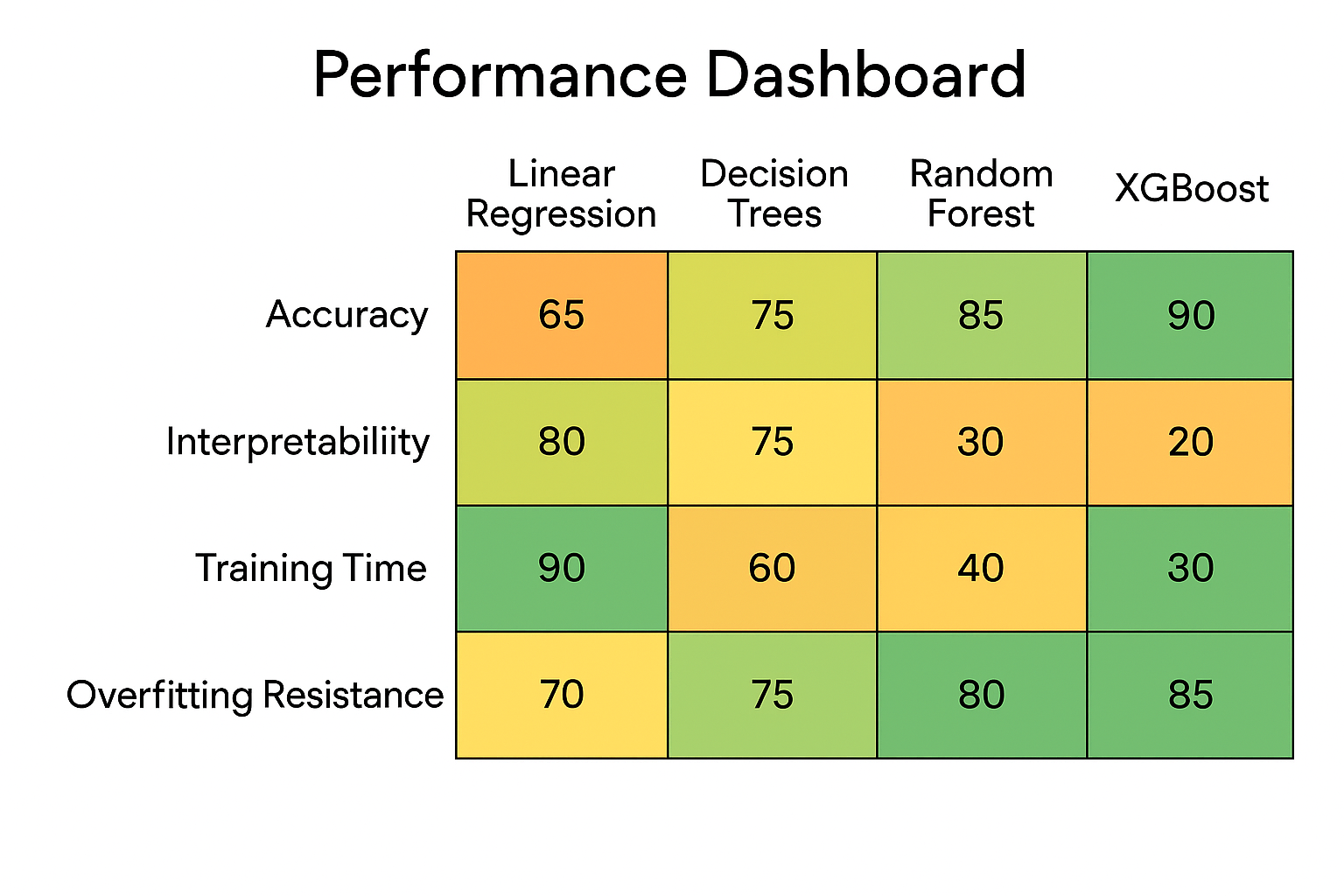
Algorithm Performance Dashboard
Compare all algorithms across different scenarios and metrics:
Comprehensive Algorithm Comparison
Select a scenario to see how different algorithms perform:
Algorithm Selection Cheat Sheet
🥇 Best Overall: XGBoost
Highest accuracy, built-in regularization, handles missing values
⚖️ Best Balance: Random Forest
Good accuracy, robust, minimal tuning required
🔍 Most Interpretable: Decision Tree
Easy to understand, visualizable rules
⚡ Fastest: Linear Models
Quick training and prediction, minimal resources
Real-World Case Studies
Explore how different algorithms solve real business problems:
🎯 Interactive Case Studies
Click on a case study to see the algorithm selection process in action:
💳 Credit Risk Assessment
Problem: Bank needs to predict loan defaults with 95%+ accuracy
Data: 50K customers, mixed numerical/categorical features
🏥 Medical Diagnosis
Problem: Diagnose disease from patient symptoms with explainable results
Data: 5K patients, interpretability critical
🚀 Startup Customer Prediction
Problem: Limited data, need quick results, tight budget
Data: 2K customers, fast iteration needed
📡 IoT Sensor Monitoring
Problem: Real-time anomaly detection, resource constraints
Data: Streaming data, edge computing limitations
Implementation Guide
Step-by-step guide to implementing your chosen algorithm in production:
From Prototype to Production
Data Preparation
- Clean and validate data
- Handle missing values
- Feature engineering
- Train/validation/test split
Algorithm Selection
- Use decision tree framework
- Consider constraints
- Baseline with simple model
- Test multiple candidates
Hyperparameter Tuning
- Cross-validation setup
- Grid/random search
- Bayesian optimization
- Early stopping
Model Validation
- Multiple metrics evaluation
- Cross-validation
- Out-of-time testing
- Feature importance analysis
Chapter 8: Final Mastery Quiz
Test your complete understanding of ML model relationships and selection:
Question 1: Algorithm Selection for Production System
You have a tabular dataset with 100K rows, mixed data types, and need maximum accuracy for a production system. Which algorithm should you choose?
Question 2: Medical Diagnosis System Requirements
For a medical diagnosis system where doctors need to understand the decision process, which approach is most appropriate?
Question 3: Random Forest vs Gradient Boosting Trade-off
What is the most important factor when choosing between Random Forest and Gradient Boosting?
Question 4: Evolution of Ensemble Methods
Which sequence best represents the evolution from simple to advanced ensemble methods?
Question 5: Bias-Variance Trade-off Understanding
Which statement best describes the bias-variance trade-off in the algorithms we studied?
Question 6: Regularization Purpose
What is the primary purpose of L1 and L2 regularization in machine learning?
Question 7: Ensemble Method Advantages
Why do ensemble methods typically outperform single models?
Question 8: Random Forest Key Features
What are the two key techniques that make Random Forest effective?
Question 9: Gradient Boosting Learning Process
How does gradient boosting differ from random forest in its learning approach?
Question 10: When to Use Linear Models
In which scenario would you choose a linear model over ensemble methods?
Question 11: XGBoost Competitive Advantages
What makes XGBoost superior to traditional gradient boosting?
Question 12: Feature Importance Analysis
Why is feature importance analysis crucial in ensemble methods?
Question 13: Cross-Validation Purpose
What is the primary benefit of using cross-validation in model selection?
Question 14: Hyperparameter Tuning Strategy
What is the recommended approach for hyperparameter tuning?
Question 15: Production Deployment Considerations
What is the most critical factor when deploying ML models to production?
Course Complete!
Congratulations! You have completed the ML Model Relationships tutorial and mastered the connections between different algorithms.
You now understand how to choose the right algorithm for your specific problem and implement it successfully in production.